I am also part of the Farama Foundation, a nonprofit organization that maintains the largest open-source RL libraries in the world.
I completed my B.Sc. in Computer Science cum laude at the Federal University of Rio Grande do Sul in 2020.
My undergraduate thesis, advised by Prof. Bruno C. da Silva, tackled the problem of reinforcement learning in continuous non-stationary environments.
My main research interests are in reinforcement learning (RL) and its use to empower artificial intelligence (AI) agents to solve real-world problems.
In my Ph.D. Thesis, I tackled the problem of how to design principled sample-efficient RL algorithms capable of learning multiple behaviors that can be combined to solve multi-task and multi-objective problems.
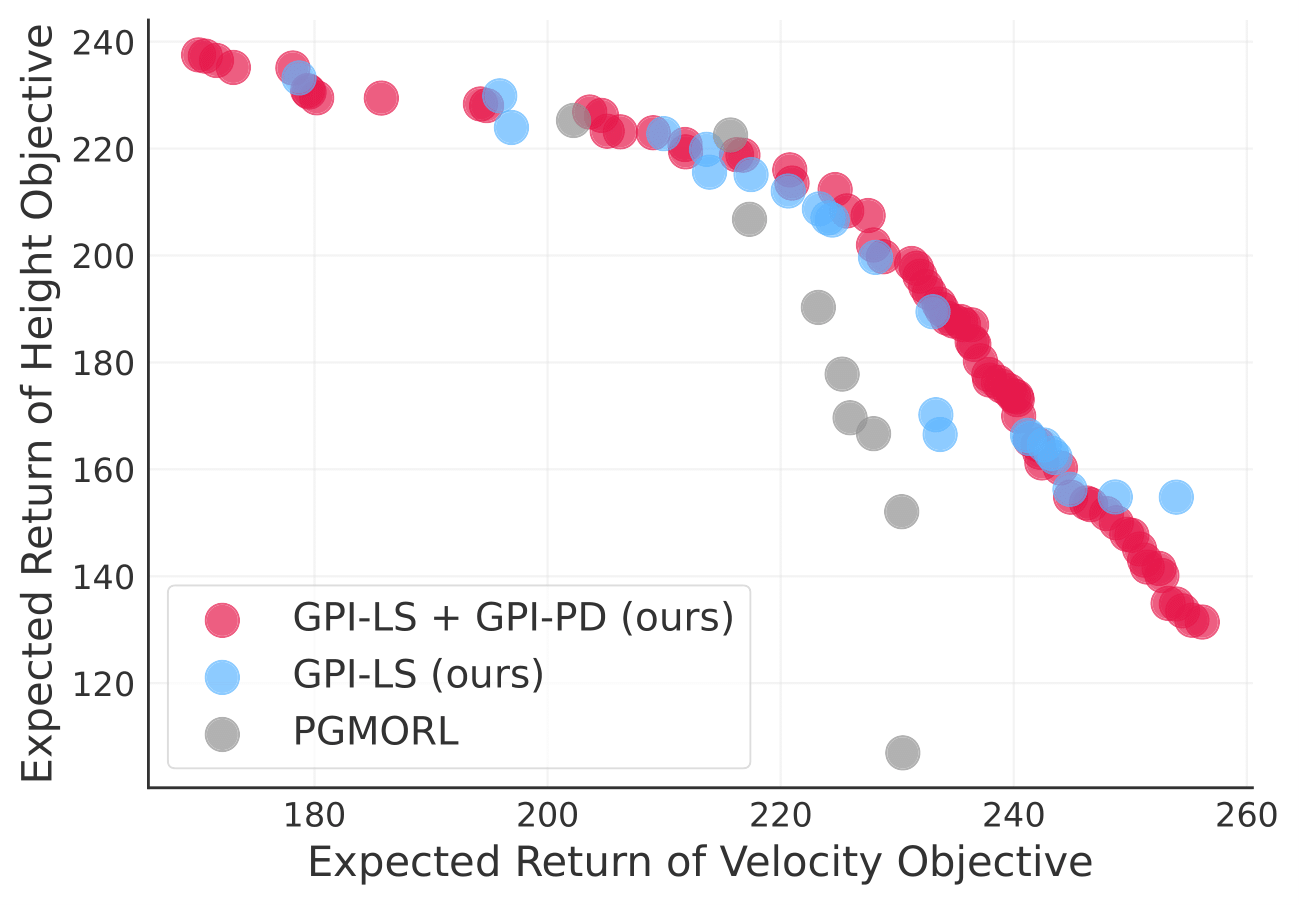
Multi-objective reinforcement learning (MORL) algorithms tackle sequential decision problems where agents may have different preferences over (possibly conflicting) reward functions. These algorithms often learn a set of policies, each optimized for a particular agent preference, that are later reused when optimizing policies for different preferences. We introduce a novel algorithm that builds upon Generalized Policy Improvement (GPI) to construct principled, formally-derived prioritization schemes that improve sample efficiency. These correspond to active-learning strategies by which the agent can identify (i) the most promising preferences/objectives to train on at each moment; and (ii) the most relevant previous experiences to learn policies for new agent preferences through a novel Dyna-style MORL method. We prove our algorithm is guaranteed to always converge to an optimal solution in a finite number of steps, or an \\ε\\-optimal solution (for a bounded \\ε\\) if the agent can only identify sub-optimal policies. Our method monotonically improves the quality of its partial solutions while learning. We also introduce a bound that characterizes the maximum utility loss (with respect to the optimal solution) incurred by intermediate policies identified by our method during learning. Finally, we propose a novel epistemic uncertainty-aware extension of GPI that exploits high-confidence lower bounds to mitigate the impact of unreliable action-value estimates in GPI policies, and prove that it provides tighter performance bounds than the current state of the art. We empirically show that our method outperforms state-of-the-art MORL algorithms in challenging multi-objective tasks.
@article{Alegre+2026,title={Generalized policy improvement for efficient and robust multi-objective reinforcement learning},author={Alegre, Lucas N. and Roijers, Diederik M. and Now{\'e}, Ann and Bazzan, Ana L. C. and {da Silva}, Bruno C.},year={2026},journal={Autonomous Agents and Multi-Agent Systems},number={1},volume={40},doi={10.1007/s10458-026-09736-w},}
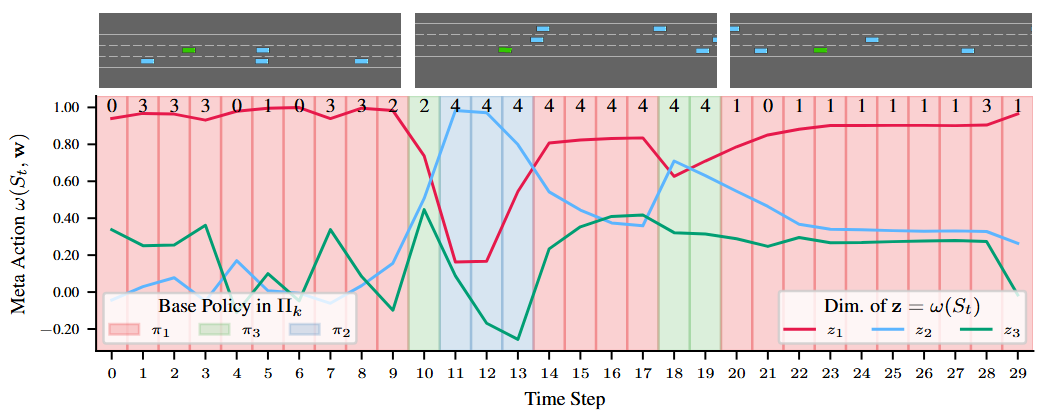
Multi-task reinforcement learning aims to quickly identify solutions for new tasks with minimal or no additional interaction with the environment. Generalized Policy Improvement (GPI) addresses this by combining a set of base policies to produce a new one that is at least as good – though not necessarily optimal – as any individual base policy. Optimality can be ensured, particularly in the linear-reward case, via techniques that compute a Convex Coverage Set (CCS). However, these are computationally expensive and do not scale to complex domains. The Option Keyboard (OK) improves upon GPI by producing policies that are at least as good – and often better. It achieves this through a learned meta-policy that dynamically combines base policies. However, its performance critically depends on the choice of base policies. This raises a key question: is there an optimal set of base policies – an optimal behavior basis – that enables zero-shot identification of optimal solutions for any linear tasks? We solve this open problem by introducing a novel method that efficiently constructs such an optimal behavior basis. We show that it significantly reduces the number of base policies needed to ensure optimality in new tasks. We also prove that it is strictly more expressive than a CCS, enabling particular classes of non-linear tasks to be solved optimally. We empirically evaluate our technique in challenging domains and show that it outperforms state-of-the-art approaches, increasingly so as task complexity increases.
@inproceedings{Alegre+2025,title={Constructing an Optimal Behavior Basis for the Option Keyboard},author={Alegre, Lucas N. and Bazzan, Ana L. C. and Barreto, André and {da Silva}, Bruno C.},booktitle={Proceedings of the Thirty-ninth Conference on Neural Information Processing Systems (NeurIPS)},year={2025},location={San Diego, USA},}
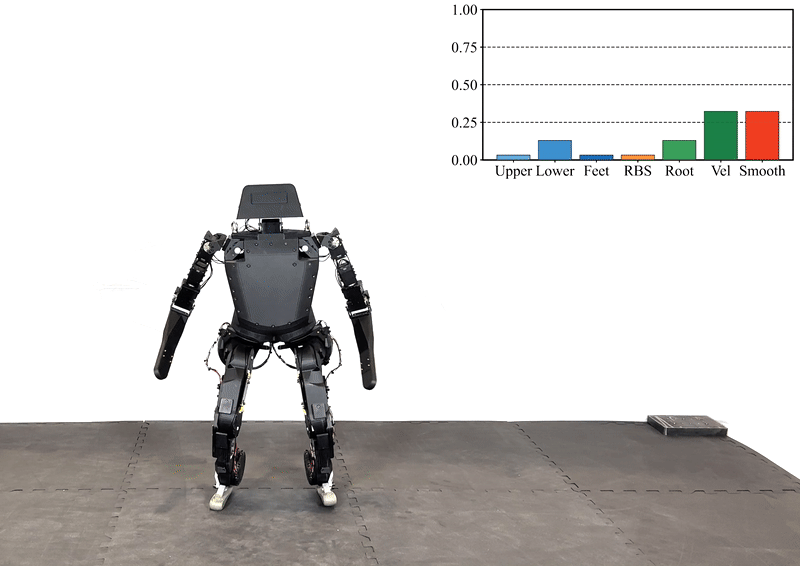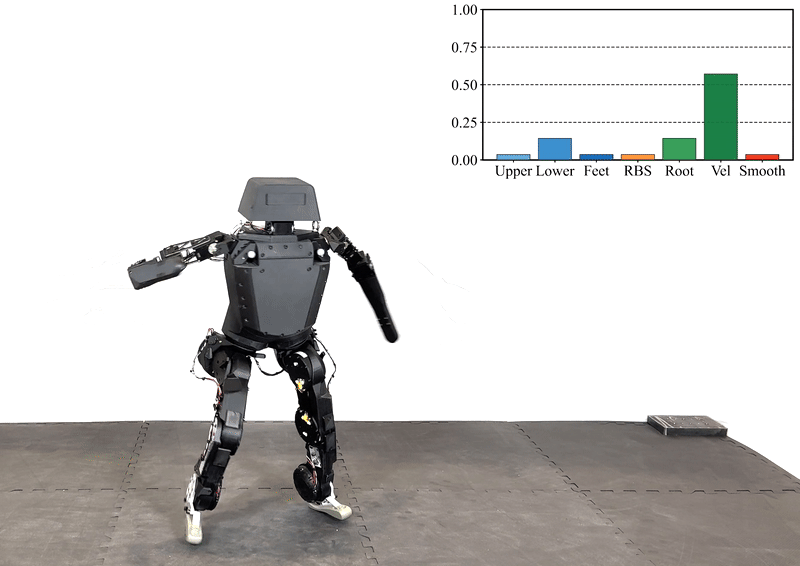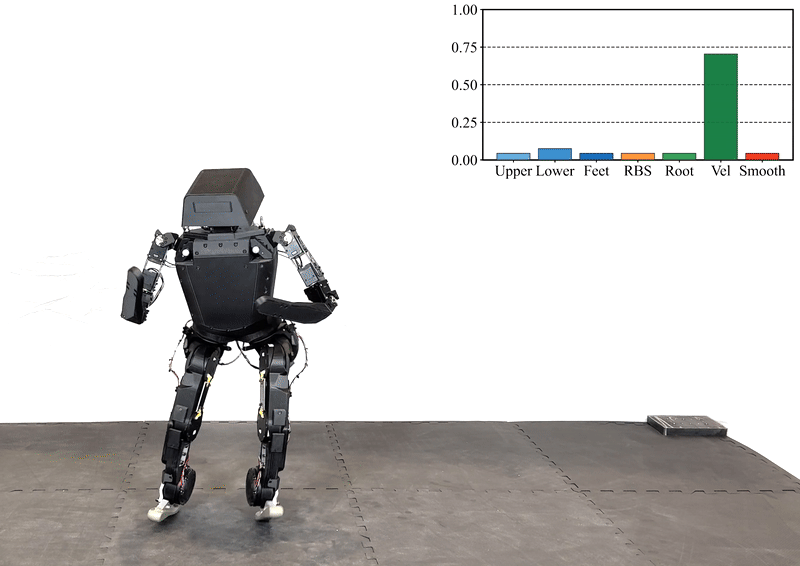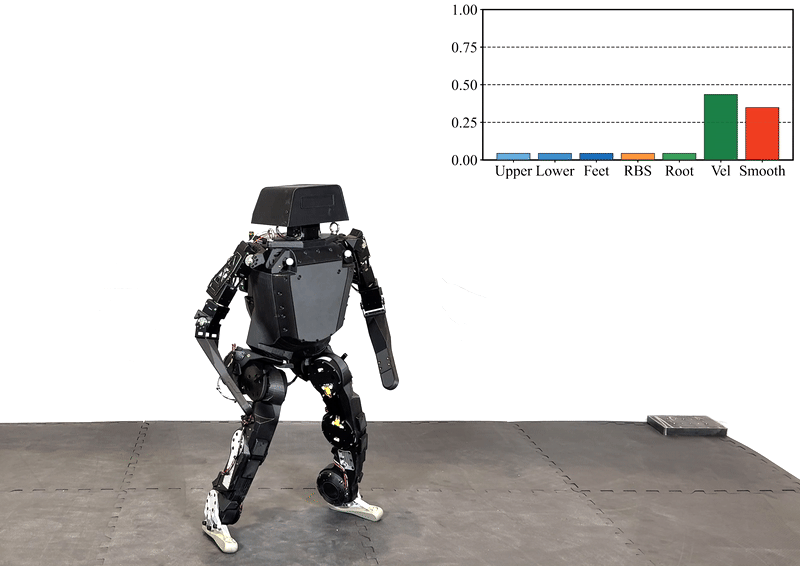
Reinforcement learning (RL) has significantly advanced the control of physics-based and robotic characters that track kinematic reference motion. However, methods typically rely on a weighted sum of conflicting reward functions, requiring extensive tuning to achieve a desired behavior. Due to the computational cost of RL, this iterative process is a tedious, time-intensive task. Furthermore, for robotics applications, the weights need to be chosen such that the policy performs well in the real world, despite inevitable sim-to-real gaps. To address these challenges, we propose a multi-objective reinforcement learning framework that trains a single policy conditioned on a set of weights, spanning the Pareto front of reward trade-offs. Within this framework, weights can be selected and tuned after training, significantly speeding up iteration time. We demonstrate how this improved workflow can be used to perform highly dynamic motions with a robot character. Moreover, we explore how weight-conditioned policies can be leveraged in hierarchical settings, using a high-level policy to dynamically select weights according to the current task. We show that the multi-objective policy encodes a diverse spectrum of behaviors, facilitating efficient adaptation to novel tasks.
@inproceedings{Alegre+2025siggraph,author={Alegre, Lucas N. and Serifi, Agon and Grandia, Ruben and Müller, David and Knoop, Espen and Bächer, Moritz},title={{AMOR}: Adaptive Character Control through Multi-Objective Reinforcement Learning},booktitle={Proceedings of the 52nd Annual Conference on Computer Graphics and Interactive Techniques (SIGGRAPH)},year={2025},location={Vancouver, Canada},}
In this work, we introduce Successor Clusters (SCs), a novel method for tackling unsupervised zero-shot reinforcement learning (RL) problems. The goal in this setting is to directly identify policies capable of optimizing any given reward functions without requiring further learning after an initial reward-free training phase. Existing state-of-the-art techniques leverage Successor Features (SFs)—functions capable of characterizing a policy’s expected discounted sum of a set of d reward features. Importantly, however, the performance of existing techniques depends critically on how well the reward features enable arbitrary reward functions of interest to be linearly approximated. We introduce a novel and principled approach for constructing reward features and prove that they allow for any Lipschitz reward functions to be approximated arbitrarily well. Furthermore, we mathematically derive upper bounds on the corresponding approximation errors. Our method constructs features by clustering the state space via a novel distance metric quantifying the minimal expected number of timesteps needed to transition between any state pairs. Building on these theoretical contributions, we introduce Successor Clusters (SCs), a variant of the successor features framework capable of predicting the time spent by a policy in different regions of the state space. We demonstrate that, after a pre-training phase, our method can approximate and maximize any new reward functions in a zero-shot manner. Importantly, we also formally show that as the number and quality of clusters increase, the set of policies induced by Successor Clusters converges to a set containing the optimal policy for any new task. Moreover, we show that our technique naturally produces interpretable features, enabling applications such as visualizing the sequence of state regions an agent is likely to visit while solving a task. Finally, we empirically demonstrate that our method outperforms stateof-the-art SF-based competitors in challenging continuous control benchmarks, achieving superior zero-shot performance and lower reward approximation error.
@article{Bagot+2025,title={Successor Clusters: A Behavior Basis for Unsupervised Zero-Shot Reinforcement Learning},author={Bagot, Louis and Alegre, Lucas N. and Latre, Steven and Mets, Kevin and da Silva, Bruno Castro},journal={Transactions on Machine Learning Research},issn={2835-8856},year={2025},}
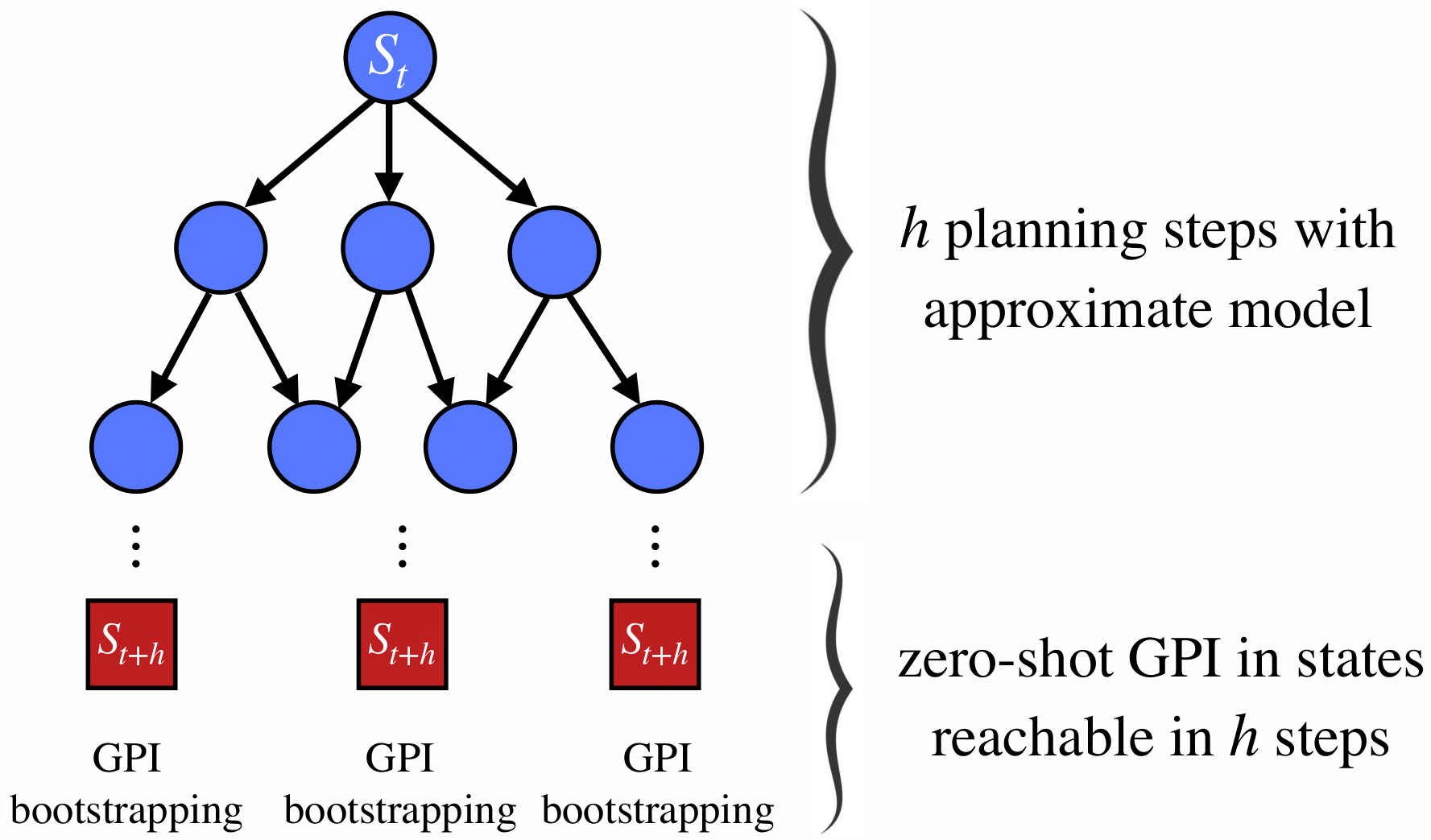
We introduce a principled method for performing zero-shot transfer in reinforcement learning (RL) by exploiting approximate models of the environment. Zero-shot transfer in RL has been investigated by leveraging methods rooted in generalized policy improvement (GPI) and successor features (SFs). Although computationally efficient, these methods are model-free: they analyze a library of policies—each solving a particular task—and identify which action the agent should take. We investigate the more general setting where, in addition to a library of policies, the agent has access to an approximate environment model. Even though model-based RL algorithms can identify near-optimal policies, they are typically computationally intensive. We introduce h-GPI, a multi-step extension of GPI that interpolates between these extremes—standard model-free GPI and full model-based planning—as a function of a parameter, h, regulating the amount of time the agent has to reason. We prove that h-GPI’s performance lower bound is strictly better than GPI’s, and show that h-GPI generally outperforms GPI as h increases. Furthermore, we prove that as h increases, h-GPI’s performance becomes arbitrarily less susceptible to sub-optimality in the agent’s policy library. Finally, we introduce novel bounds characterizing the gains achievable by h-GPI as a function of approximation errors in both the agent’s policy library and its (possibly learned) model. These bounds strictly generalize those known in the literature. We evaluate h-GPI on challenging tabular and continuous-state problems under value function approximation and show that it consistently outperforms GPI and state-of-the-art competing methods under various levels of approximation errors.
@inproceedings{Alegre+2023neurips,author={Alegre, Lucas N. and Bazzan, Ana L. C. and Now{\'e}, Ann and {da Silva}, Bruno C.},title={Multi-Step Generalized Policy Improvement by Leveraging Approximate Models},booktitle={Proceedings of the Thirty-seventh Conference on Neural Information Processing Systems (NeurIPS)},volume={36},location={New Orleans, USA},year={2023},}
Multi-objective reinforcement learning algorithms (MORL) extend standard reinforcement learning (RL) to scenarios where agents must optimize multiple—potentially conflicting—objectives, each represented by a distinct reward function. To facilitate and accelerate research and benchmarking in multi-objective RL problems, we introduce a comprehensive collection of software libraries that includes: (i) MO-Gymnasium, an easy-to-use and flexible API enabling the rapid construction of novel MORL environments. It also includes more than 20 environments under this API. This allows researchers to effortlessly evaluate any algorithms on any existing domains; (ii) MORL-Baselines, a collection of reliable and efficient implementations of state-of-the-art MORL algorithms, designed to provide a solid foundation for advancing research. Notably, all algorithms are inherently compatible with MO-Gymnasium; and (iii) a thorough and robust set of benchmark results and comparisons of MORL-Baselines algorithms, tested across various challenging MO-Gymnasium environments. These benchmarks were constructed to serve as guidelines for the research community, underscoring the properties, advantages, and limitations of each particular state-of-the-art method.
@inproceedings{Felten+2023,author={Felten*, Florian and Alegre*, Lucas N. and Now{\'e}, Ann and Bazzan, Ana L. C. and Talbi, El-Ghazali and Danoy, Gr{\'e}goire and {da Silva}, Bruno C.},title={A Toolkit for Reliable Benchmarking and Research in Multi-Objective Reinforcement Learning},booktitle={Proceedings of the Thirty-seventh Conference on Neural Information Processing Systems (NeurIPS) Track on Datasets and Benchmarks},volume={36},location={New Orleans, USA},year={2023},}
Multi-objective reinforcement learning (MORL) algorithms tackle sequential decision problems where agents may have different preferences over (possibly conflicting) reward functions. Such algorithms often learn a set of policies (each optimized for a particular agent preference) that can later be used to solve problems with novel preferences. We introduce a novel algorithm that uses Generalized Policy Improvement (GPI) to define principled, formally-derived prioritization schemes that improve sample-efficient learning. They implement active-learning strategies by which the agent can (i) identify the most promising preferences/objectives to train on at each moment, to more rapidly solve a given MORL problem; and (ii) identify which previous experiences are most relevant when learning a policy for a particular agent preference, via a novel Dyna-style MORL method. We prove our algorithm is guaranteed to always converge to an optimal solution in a finite number of steps, or an ϵ-optimal solution (for a bounded ϵ) if the agent is limited and can only identify possibly sub-optimal policies. We also prove that our method monotonically improves the quality of its partial solutions while learning. Finally, we introduce a bound that characterizes the maximum utility loss (with respect to the optimal solution) incurred by the partial solutions computed by our method throughout learning. We empirically show that our method outperforms state-of-the-art MORL algorithms in challenging multi-objective tasks, both with discrete and continuous state spaces.
@inproceedings{Alegre+2023,title={Sample-Efficient Multi-Objective Learning via Generalized Policy Improvement Prioritization},author={Alegre, Lucas N. and Roijers, Diederik M. and Now{\'e}, Ann and Bazzan, Ana L. C. and {da Silva}, Bruno C.},booktitle={Proc. of the 22nd International Conference on Autonomous Agents and Multiagent Systems (AAMAS)},year={2023},}
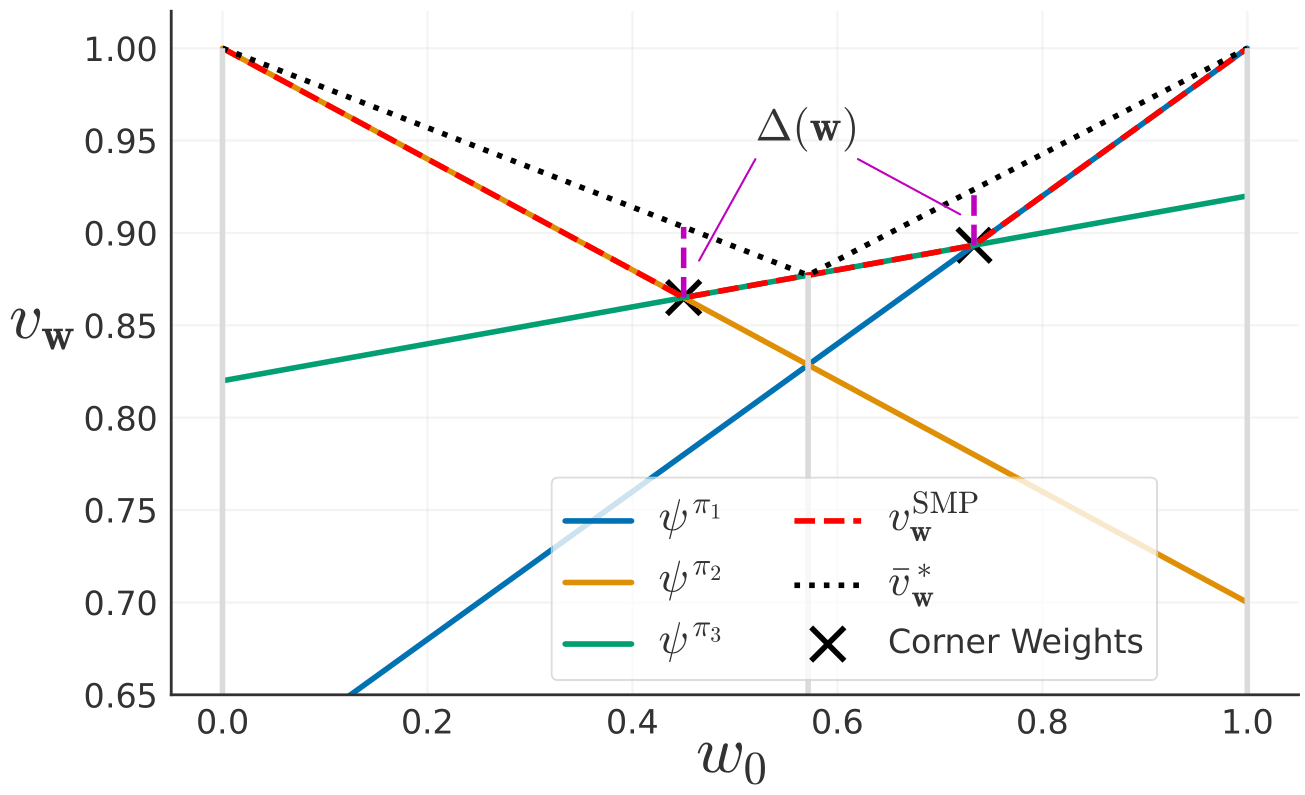
In many real-world applications, reinforcement learning (RL) agents might have to solve multiple tasks, each one typically modeled via a reward function. If reward functions are expressed linearly, and the agent has previously learned a set of policies for different tasks, successor features (SFs) can be exploited to combine such policies and identify reasonable solutions for new problems. However, the identified solutions are not guaranteed to be optimal. We introduce a novel algorithm that addresses this limitation. It allows RL agents to combine existing policies and directly identify optimal policies for arbitrary new problems, without requiring any further interactions with the environment. We first show (under mild assumptions) that the transfer learning problem tackled by SFs is equivalent to the problem of learning to optimize multiple objectives in RL. We then introduce an SF-based extension of the Optimistic Linear Support algorithm to learn a set of policies whose SFs form a convex coverage set. We prove that policies in this set can be combined via generalized policy improvement to construct optimal behaviors for any new linearly-expressible tasks, without requiring any additional training samples. We empirically show that our method outperforms state-of-the-art competing algorithms both in discrete and continuous domains under value function approximation.
@inproceedings{Alegre+2022,title={Optimistic Linear Support and Successor Features as a Basis for Optimal Policy Transfer},author={Alegre, Lucas N. and Bazzan, Ana L. C. and {da Silva}, Bruno C.},booktitle={Proceedings of the 39th International Conference on Machine Learning},pages={394--413},year={2022},editor={Chaudhuri, Kamalika and Jegelka, Stefanie and Song, Le and Szepesvari, Csaba and Niu, Gang and Sabato, Sivan},volume={162},series={Proceedings of Machine Learning Research},publisher={PMLR},}
Non-stationary environments are challenging for reinforcement learning algorithms. If the state transition and/or reward functions change based on latent factors, the agent is effectively tasked with optimizing a behavior that maximizes performance over a possibly infinite random sequence of Markov Decision Processes (MDPs), each of which drawn from some unknown distribution. We call each such MDP a context. Most related works make strong assumptions such as knowledge about the distribution over contexts, the existence of pre-training phases, or a priori knowledge about the number, sequence, or boundaries between contexts. We introduce an algorithm that efficiently learns policies in non-stationary environments. It analyzes a possibly infinite stream of data and computes, in real-time, high-confidence change-point detection statistics that reflect whether novel, specialized policies need to be created and deployed to tackle novel contexts, or whether previously-optimized ones might be reused. We show that (i) this algorithm minimizes the delay until unforeseen changes to a context are detected, thereby allowing for rapid responses; and (ii) it bounds the rate of false alarm, which is important in order to minimize regret. Our method constructs a mixture model composed of a (possibly infinite) ensemble of probabilistic dynamics predictors that model the different modes of the distribution over underlying latent MDPs. We evaluate our algorithm on high-dimensional continuous reinforcement learning problems and show that it outperforms state-of-the-art (model-free and model-based) RL algorithms, as well as state-of-the-art meta-learning methods specially designed to deal with non-stationarity.
@inproceedings{Alegre+2021aamas,title={Minimum-Delay Adaptation in Non-Stationary Reinforcement Learning via Online High-Confidence Change-Point Detection},author={Alegre, Lucas N. and Bazzan, Ana L. C. and {da Silva}, Bruno C.},booktitle={Proceedings of the 20th International Conference on Autonomous Agents and Multiagent Systems (AAMAS)},location={Virtual Event, United Kingdom},year={2021},pages={97--105},isbn={9781450383073},publisher={International Foundation for Autonomous Agents and Multiagent Systems},address={Richland, SC},note={Best Paper Award at LXAI Workshop @ ICML 2021}}
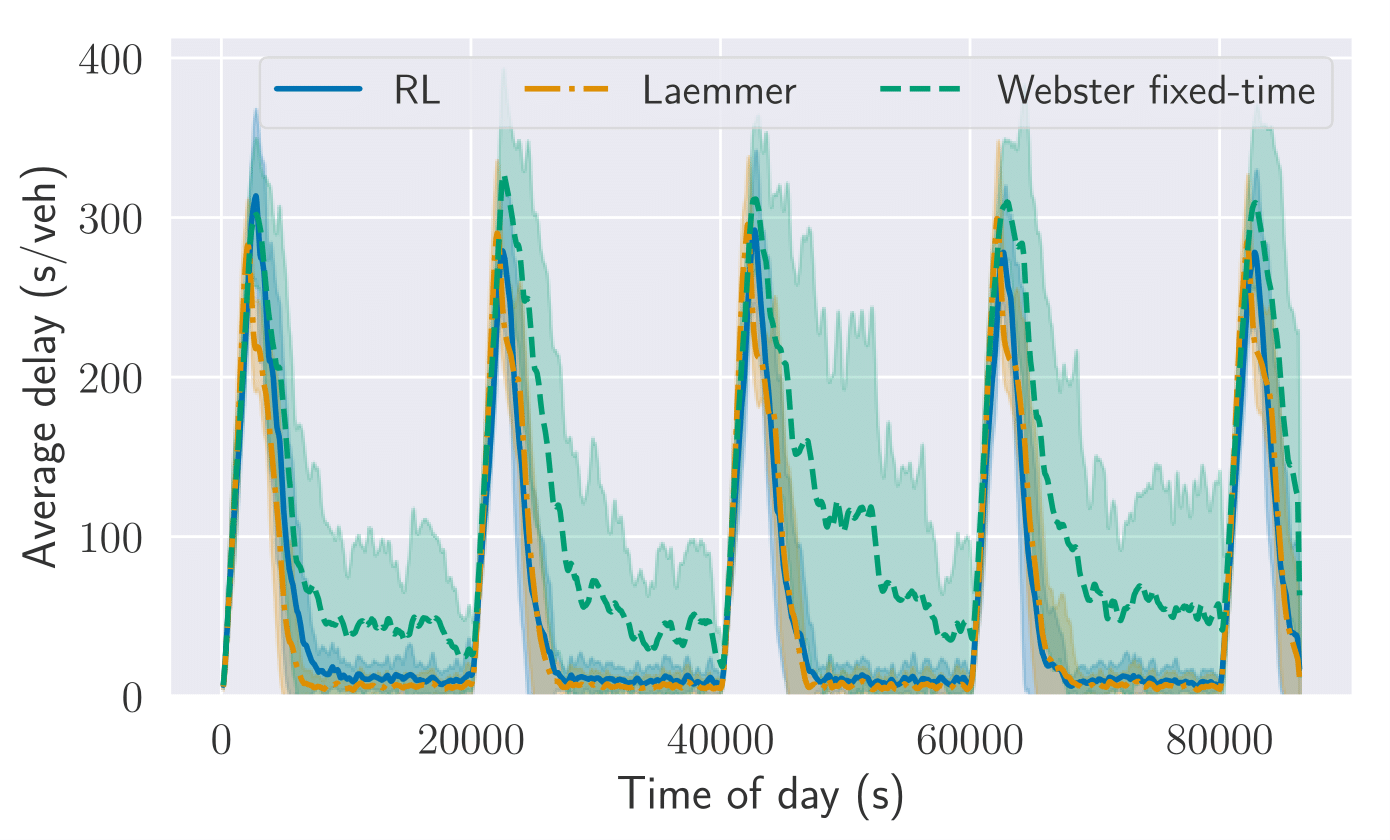
Reinforcement learning is an efficient, widely used machine learning technique that performs well in problems with a reasonable number of states and actions. This is rarely the case regarding control-related problems, as for instance controlling traffic signals, where the state space can be very large. One way to deal with the curse of dimensionality is to use generalization techniques such as function approximation. In this paper, a linear function approximation is used by traffic signal agents in a network of signalized intersections. Specifically, a true online SARSA (λ) algorithm with Fourier basis functions (TOS(λ)-FB) is employed. This method has the advantage of having convergence guarantees and error bounds, a drawback of non-linear function approximation. In order to evaluate TOS(λ)-FB, we perform experiments in variations of an isolated intersection scenario and a scenario of the city of Cottbus, Germany, with 22 signalized intersections, implemented in MATSim. We compare our results not only to fixed-time controllers, but also to a state-of-the-art rule-based adaptive method, showing that TOS(λ)-FB shows a performance that is highly superior to the fixed-time, while also being at least as efficient as the rule-based approach. For more than half of the intersections, our approach leads to less congestion and delay, without the need for the knowledge that underlies the rule-based approach.
@article{Alegre+2021its,author={Alegre, Lucas N. and Ziemke, Theresa and Bazzan, Ana L. C.},title={Using Reinforcement Learning to Control Traffic Signals in a Real-World Scenario: an Approach Based on Linear Function Approximation},journal={IEEE Transactions on Intelligent Transportation Systems},pages={},doi={10.1109/TITS.2021.3091014},year={2021},}
Reinforcement learning is an efficient, widely used machine learning technique that performs well when the state and action spaces have a reasonable size. This is rarely the case regarding control-related problems, as for instance controlling traffic signals. Here, the state space can be very large. In order to deal with the curse of dimensionality, a rough discretization of such space can be employed. However, this is effective just up to a certain point. A way to mitigate this is to use techniques that generalize the state space such as function approximation. In this paper, a linear function approximation is used. Specifically, SARSA(λ) with Fourier basis features is implemented to control traffic signals in the agent-based transport simulation MATSim. The results are compared not only to trivial controllers such as fixed-time, but also to state-of-the-art rule-based adaptive methods. It is concluded that SARSA(λ) with Fourier basis features is able to outperform such methods, especially in scenarios with varying traffic demands or unexpected events.
@article{Ziemke+2021,author={Ziemke, Theresa and Alegre, Lucas N. and Bazzan, Ana L. C.},title={Reinforcement Learning vs. Rule-Based Adaptive Traffic Signal Control: A Fourier Basis Linear Function Approximation for Traffic Signal Control},journal={AI Communications},year={2021},pages={89--103},doi={10.3233/AIC-201580},}
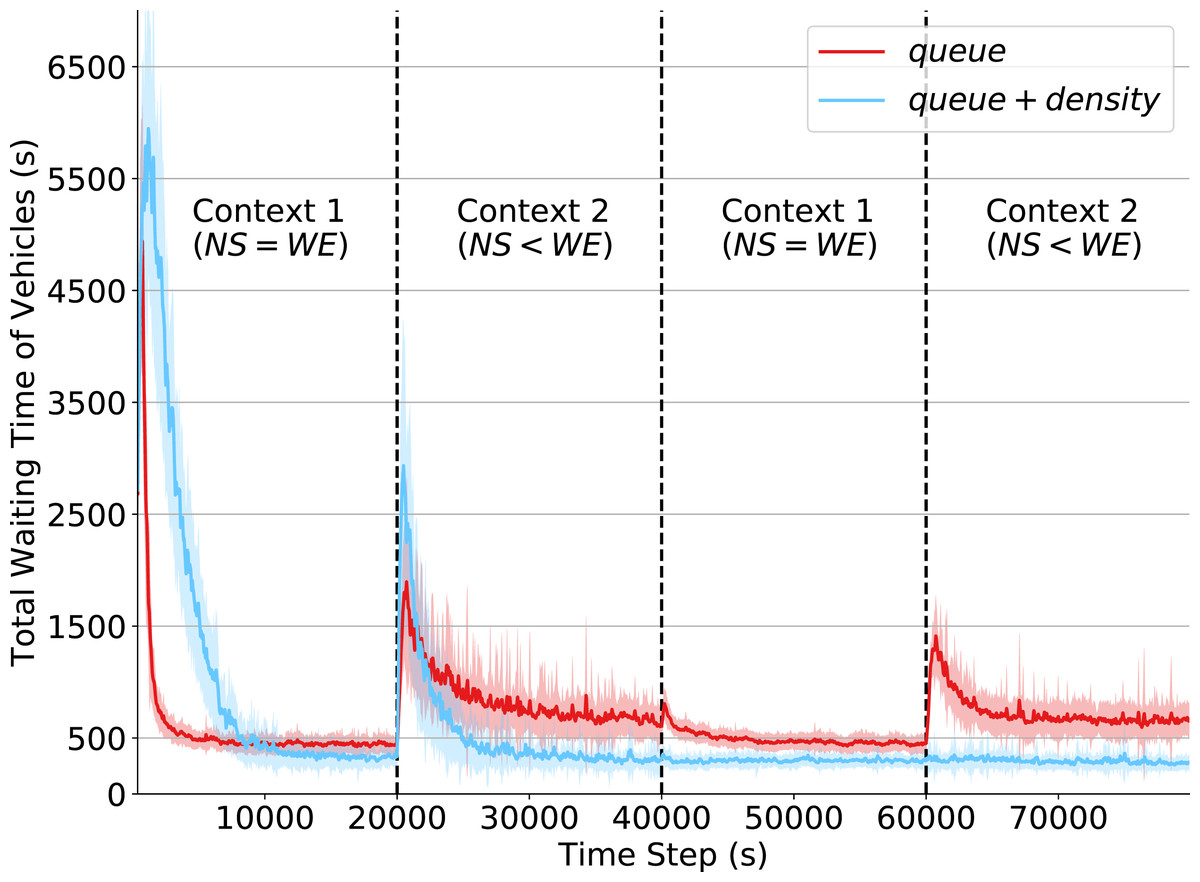
In reinforcement learning (RL), dealing with non-stationarity is a challenging issue. However, some domains such as traffic optimization are inherently non-stationary. Causes for and effects of this are manifold. In particular, when dealing with traffic signal controls, addressing non-stationarity is key since traffic conditions change over time and as a function of traffic control decisions taken in other parts of a network. In this paper we analyze the effects that different sources of non-stationarity have in a network of traffic signals, in which each signal is modeled as a learning agent. More precisely, we study both the effects of changing the context in which an agent learns (e.g., a change in flow rates experienced by it), as well as the effects of reducing agent observability of the true environment state. Partial observability may cause distinct states (in which distinct actions are optimal) to be seen as the same by the traffic signal agents. This, in turn, may lead to sub-optimal performance. We show that the lack of suitable sensors to provide a representative observation of the real state seems to affect the performance more drastically than the changes to the underlying traffic patterns.
@article{Alegre+2021peerj,title={Quantifying the Impact of Non-Stationarity in Reinforcement Learning-Based Traffic Signal Control},author={Alegre, Lucas N. and Bazzan, Ana L. C. and {da Silva}, Bruno C.},volume={7},issn={2376-5992},url={http://dx.doi.org/10.7717/peerj-cs.575},doi={10.7717/peerj-cs.575},journal={PeerJ Computer Science},publisher={PeerJ},year={2021},pages={e575},}
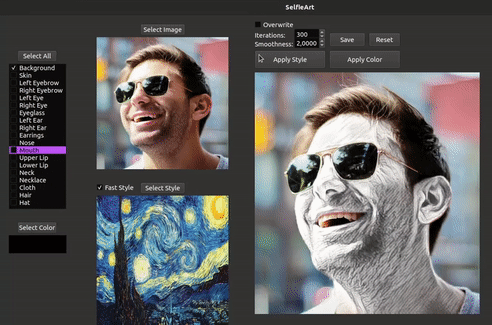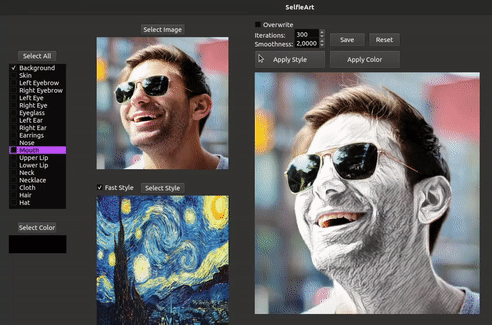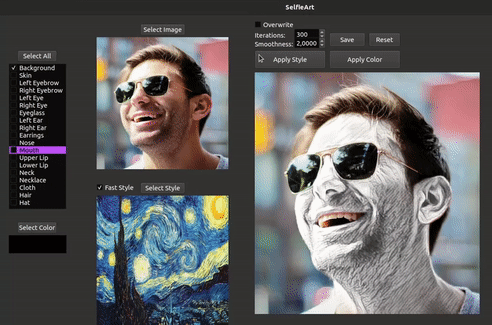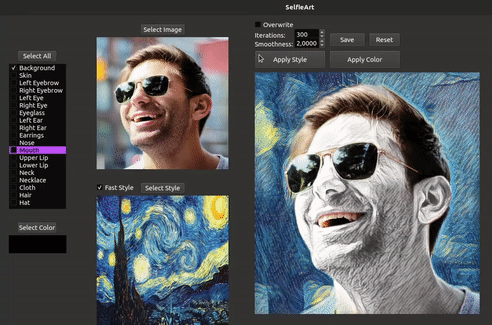
We introduce SelfieArt, an interactive technique for performing multi-style transfer for portraits and videos. Our method provides a simple and intuitive way of producing exquisite artistic results that combine multiple styles in a harmonious fashion. It uses face parsing and a multi-style transfer model to apply different styles to the various semantic segments. This is achieved using parameterized soft masks, allowing users to adjust the smoothness of the transitions between stylized regions in real-time. We demonstrate the effectiveness of our solution on a large set of images and videos. Given its flexibility, speed, and quality of results, our solution can be a valuable tool for creative exploration, allowing anyone to transform photographs and drawings in world-class artistic results.
@inproceedings{AlegreOliveira2020,author={Alegre, Lucas N. and Oliveira, Manuel M.},title={SelfieArt: Interactive Multi-Style Transfer for Selfies and Videos with Soft Transitions},booktitle={Proceedings of the 2020 33rd SIBGRAPI Conference on Graphics, Patterns and Images},year={2020},pages={17--22},doi={10.1109/SIBGRAPI51738.2020.00011},}
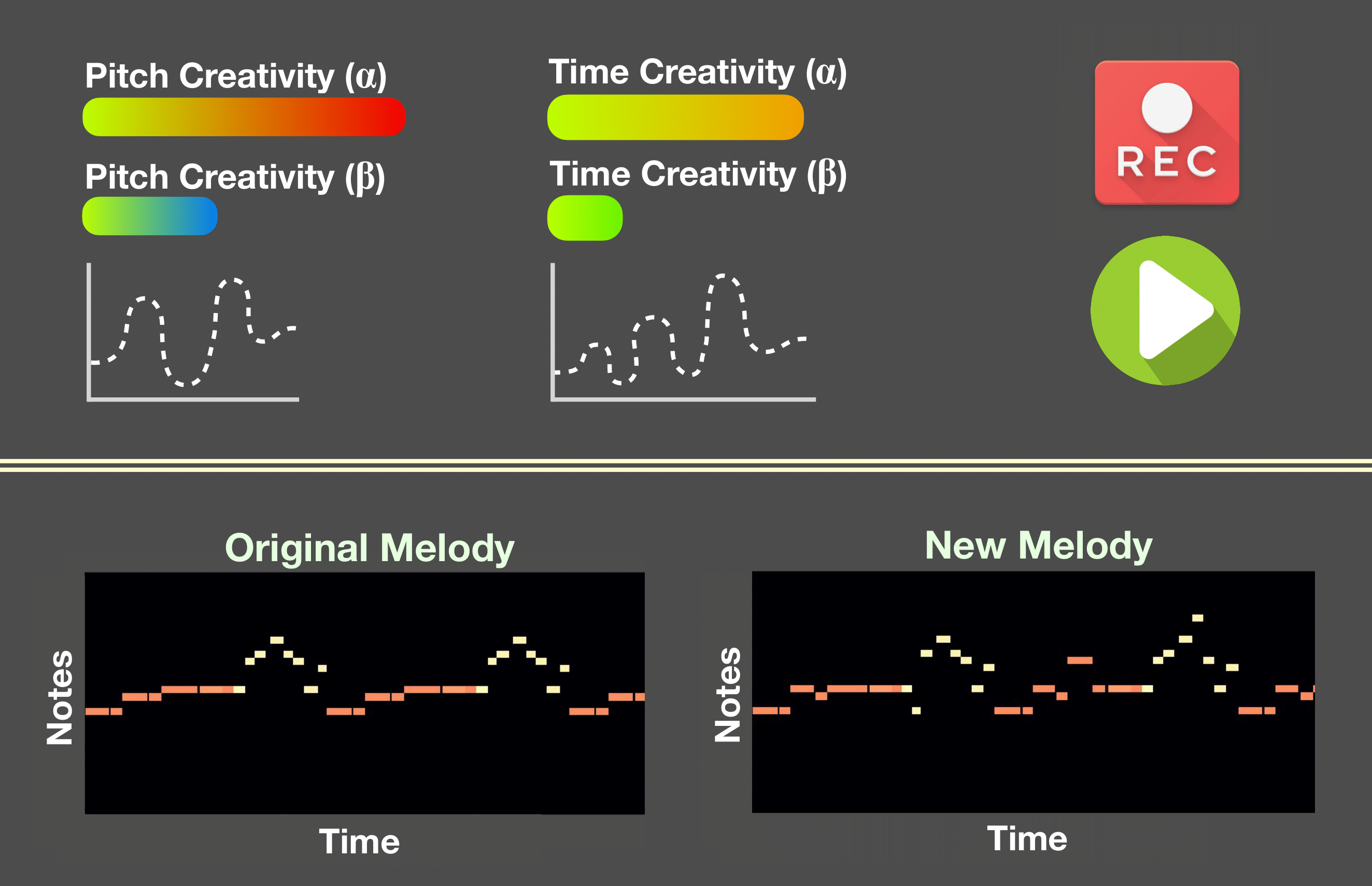
We introduce a machine learning technique to autonomously generate novel melodies that are variations of an arbitrary base melody. These are produced by a neural network that ensures that (with high probability) the melodic and rhythmic structure of the new melody is consistent with a given set of sample songs. We train a Variational Autoencoder network to identify a low-dimensional set of variables that allows for the compression and representation of sample songs. By perturbing these variables with Perlin Noise—a temporally-consistent parameterized noise function—it is possible to generate smoothly-changing novel melodies. We show that (1) by regulating the amount of noise, one can specify how much of the base song will be preserved; and (2) there is a direct correlation between the noise signal and the differences between the statistical properties of novel melodies and the original one. Users can interpret the controllable noise as a type of "creativity knob": the higher it is, the more leeway the network has to generate significantly different melodies. We present a physical prototype that allows musicians to use a keyboard to provide base melodies and to adjust the network’s "creativity knobs" to regulate in real-time the process that proposes new melody ideas.
@inproceedings{weber+2019,author={Weber, Aline and Alegre, Lucas N. and Torresen, Jim and {da Silva}, Bruno C.},booktitle={Proceedings of the International Conference on New Interfaces for Musical Expression},year={2019},}